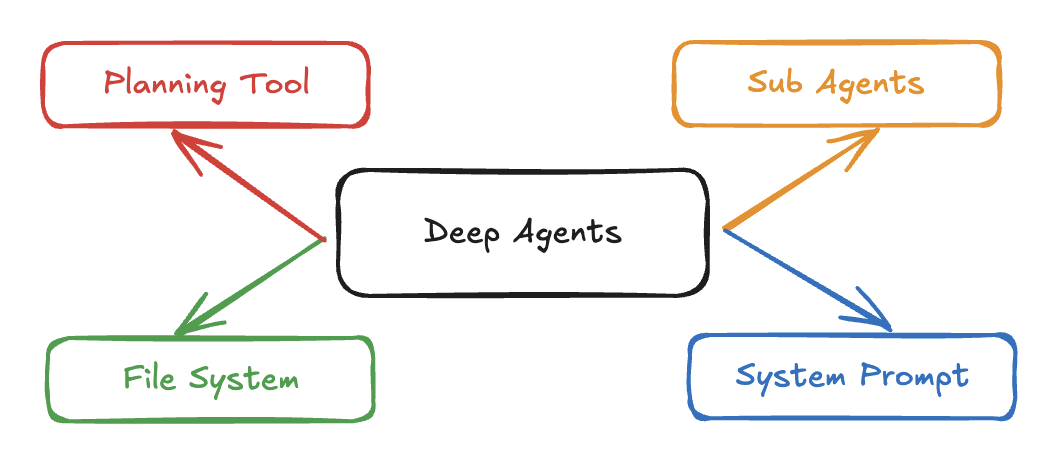
AI快站
综合介绍
AI快站是一个免费的在线服务平台,它的核心功能是让用户可以一键对比多种顶级的开源OCR(光学字符识别)模型。用户上传PDF或图片文件后,平台能够调用包括MinerU、MonkeyOCR、Docling在内的七种不同模型进行文档解析和文字识别。这个过程就像一个“竞技场”,让不同的模型处理同一个文件,然后将识别结果并列展示出来。这样做的目的是为了帮助用户根据自己文件的特点和需求(例如,是需要高精度的学术论文解析,还是快速的图片文字提取),直观地比较并找到效果最好的那个模型。平台处理速度快,支持多种结果格式导出,并且强调数据安全,为企业和个人在文档数字化、数据提取等工作上提供了一个便捷、高效且无成本的测试解决方案。
功能列表
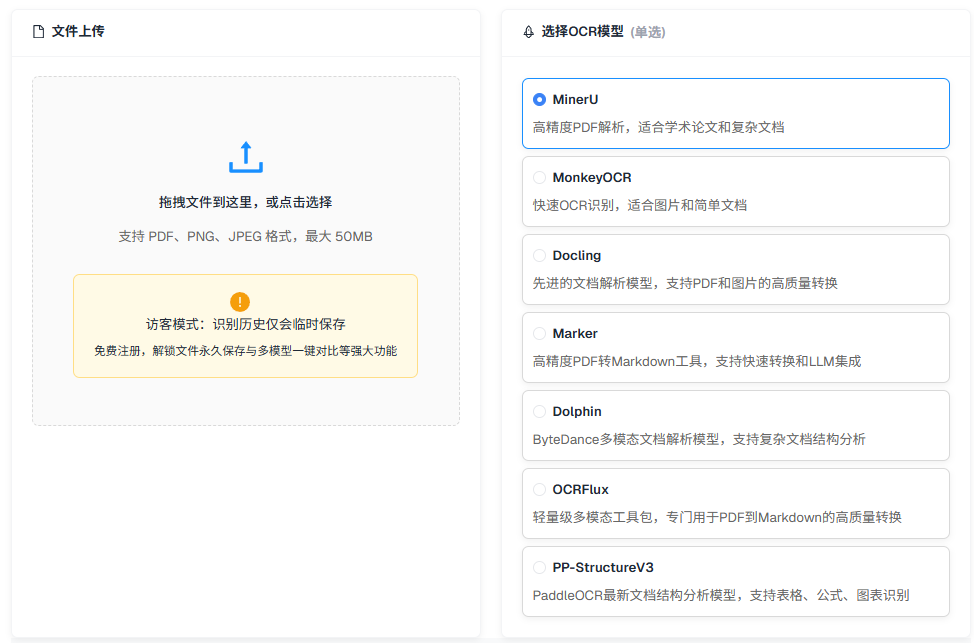
- 多模型对比:平台集成了七种主流的OCR模型(MinerU, MonkeyOCR, Docling, Marker, Dolphin, OCRFlux, PP-StructureV3),用户可以上传一次文件,然后分别查看每个模型的识别效果,方便找到最适合的方案。
- 多种文件格式支持:支持上传常见的文档和图片格式,包括
PDF、PNG、JPEG,文件大小上限为50MB。 - 多种导出格式:识别完成后的文本内容可以导出为
TXT纯文本文件、Markdown文档,以及JSON结构化数据,方便进行后续的编辑或数据分析。 - 结果在线预览:识别结果可以直接在网页上查看,并提供原文对照功能,方便用户快速检查识别的准确性。
- 数据安全:平台声称从数据传输到存储都采用严格的管理策略,以保护用户的隐私和商业机密。
- 云端部署选项:除了直接使用在线服务,平台也支持私有云和公有云部署,为有特殊需求的企业提供了灵活的选择。
- 访客模式与注册模式:未注册的访客可以直接上传文件进行测试,但识别历史只会临时保存。注册后,用户可以永久保存文件记录,并使用更强大的对比功能。
使用帮助
AI快站提供了一个非常直观的操作流程,让即便是初次接触OCR工具的用户也能快速上手。下面将详细介绍如何使用这个平台完成文档的文字识别。
第一步:准备并上传文件
首先,你需要准备好希望识别的文档或图片。平台支持三种常见的文件格式:PDF、PNG和JPEG。请确保单个文件的大小没有超过50MB的限制。
进入网站首页,你会看到一个非常显眼的文件上传区域。你有两种方式可以上传文件:
- 拖拽上传:直接从你的电脑文件夹中,用鼠标左键按住文件,然后拖拽到网页的虚线框区域内,松开鼠标即可。
- 点击选择:点击上传区域中的“点击选择”按钮,会弹出你电脑的文件选择窗口。在窗口中找到你的文件,点击“打开”或“确定”即可上传。
平台支持批量上传,你可以一次性选择多个文件进行处理。
第二步:选择OCR模型
文件上传成功后,下一步是选择你想要使用的OCR模型。在上传区域的下方,你会看到一个模型选择列表。平台目前提供七种不同的模型,每种模型都有其独特的优势和适用场景:
MinerU: 适合处理包含复杂公式和表格的学术论文,精度高。MonkeyOCR: 识别速度快,适合处理图片或结构简单的文档。Docling: 一种先进的文档解析模型,能高质量地转换PDF和图片。Marker: 专门用于将PDF转换为Markdown格式,对需要进行二次编辑和使用大语言模型(LLM)处理的用户非常友好。Dolphin: 由字节跳动开发的多模态文档解析模型,擅长分析复杂文档的结构。OCRFlux: 一个轻量级的工具包,专注于高质量地将PDF转换为Markdown。PP-StructureV3: 来自PaddleOCR的最新技术,特别擅长识别文档中的表格、公式和图表。
如果你不确定哪个模型最适合,可以先选择任意一个模型进行测试。平台的特色就在于让你能轻松对比,所以你可以稍后再次上传文件并选用其他模型来观察效果差异。
第三步:开始处理
选择好模型后,点击页面上的“开始处理”或类似的按钮,平台就会立即启动OCR识别任务。在处理过程中,你可以看到实时的进度显示。AI快站利用了GPU加速技术,所以通常处理速度会非常快,即使是多页的PDF文件,也只需要很短的时间就能完成。
第四步:查看与对比结果
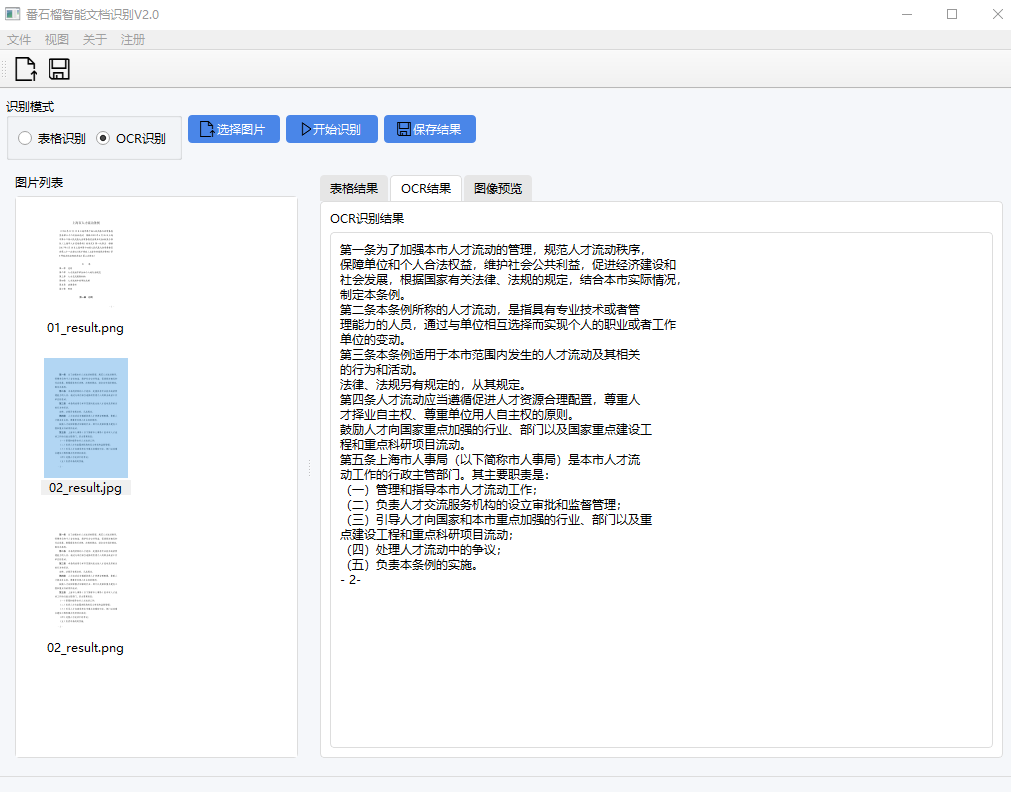
处理完成后,网页会自动跳转到结果展示页面。在这里,你可以非常方便地查看识别效果。
- 文本预览:页面会直接展示识别出的所有文字内容。
- 原文对照:通常会提供一个分栏视图,左边是你的原始图片或PDF页面,右边是对应的识别文字。这样你可以逐行逐句地检查识别的准确率,看看是否有错字、漏字或者格式错误。
- 格式切换:你可以选择以纯文本(TXT)、Markdown等不同格式预览结果。特别是当你使用
Marker这类模型时,可以直接看到排版好的Markdown效果。
如果你想对比不同模型的效果,只需要重复以上步骤,每次选用不同的OCR模型,然后分别观察其识别结果,找出最满足你需求的那个。
第五步:下载与导出
当你对识别结果满意后,就可以将其下载到你的电脑上。在结果页面的显著位置,你会找到下载或导出的按钮。平台提供多种导出格式:
TXT文本文件: 最基础的纯文本格式,兼容所有文本编辑器。Markdown文档: 保留了部分格式(如标题、列表、粗体等),非常适合用于笔记、报告撰写和网站发布。JSON结构数据: 将文档内容结构化输出,对于需要进行程序化数据提取和分析的开发者来说非常有用。PDF标注文件: 部分模型可能支持将识别结果标注回原PDF文件上。
选择你需要的格式,点击下载即可。整个流程至此结束,无需安装任何软件,所有操作都在浏览器中完成,非常便捷。
应用场景
- 企业文档数字化企业内部有大量的纸质文件,如合同、发票、报告等。通过AI快站,可以快速将这些文档扫描成图片或PDF后,批量转换为可编辑、可搜索的电子文本,极大地提升了资料归档和检索的效率,降低了人工录入的成本和错误率。
- 学术研究与学习学生和研究人员经常需要处理大量的学术论文和参考书籍。使用
MinerU这类高精度模型,可以准确地从PDF中提取文字、公式和表格,方便进行文献引用、笔记整理和数据分析,大大减轻了手动摘抄的负担。 - 金融行业单据处理金融机构每天需要处理海量的身份证、银行卡、票据等文件。AI快站提供的高准确率识别服务,能够帮助银行或保险公司实现对这些关键信息的自动录入和审核,确保了数据的准确性,同时加快了业务处理流程。
- 软件开发与数据分析开发者在构建需要文本提取功能的应用时,可以使用AI快站来测试和比较不同开源OCR引擎的性能。通过对比,可以选择最适合项目需求的模型,并利用平台提供的
JSON格式输出,轻松地将识别出的结构化数据集成到自己的程序中。
QA
- 这个平台是完全免费的吗?平台提供免费使用的访客模式和注册模式。对于大多数临时性的识别需求,免费版的配额是足够的。注册后可以解锁永久文件保存等功能。对于商业用途,它也提供私有化部署方案。
- 我应该如何选择最适合我的OCR模型?这取决于你的文件类型和需求。如果你的文件是格式复杂的学术论文,可以优先尝试
MinerU或PP-StructureV3。如果只是想快速识别图片里的简单文字,MonkeyOCR速度很快。如果希望输出Markdown格式,Marker是最佳选择。最好的方法是上传你的文件,然后用两到三个你认为可能合适的模型分别处理一次,直接对比结果。 - 上传的文件安全吗?根据网站介绍,平台声称实施了严格的数据安全策略,覆盖了文件从上传、服务器处理到存储的全过程,目的是为了保护用户的隐私和商业机密。对于极其敏感的数据,用户也可以考虑其提供的私有云部署方案。
- 识别结果不准确怎么办?首先,可以尝试更换一个OCR模型,因为不同模型对不同类型文档的识别能力有差异。其次,确保你上传的原始文件尽可能清晰,图片歪斜、分辨率过低或光线不佳都会影响识别准确率。
- 平台是否支持识别手写文字?网站介绍中主要强调的是对印刷体(PDF、图片中的标准字体)的识别,并未明确提及支持手写体识别。通常手写体的识别难度远高于印刷体,其识别效果可能不佳。